Ansible - Les playbooks
Découverte des playbooks, élément essentiel d'Ansible qui va nous permettre d'organiser et structurer nos tâches !
- Préambule
- Pré-requis
- Introduction
- Les playbooks
- Les tâches
- Point de progression
- Aller plus loin avec les sources

Préambule
Ce cours est utilisé dans le cadre de TP au sein de l'IUT Lyon 1. Il est notamment dispensé à des étudiants peu ou pas familiers avec les stratégies d'automatisation et de déploiement des infrastructures. Bien que très axé débutants il peut également représenté une possibilité de monter « rapidement » pour certaines équipes sur les principes fondamentaux d'Ansible afin de disposer du bagage minimal nécessaire à son utilisation.
Il s'agit bien évidemment de supports à vocation pédagogique qui ne sont pas toujours transposables à une activité professionnelle.
Pré-requis
Disposer d'un environnement de travail Ansible fonctionnel, si ça n'est pas encore le cas vous pouvez jeter un oeil ici !
Introduction
Un playbook est un élément central pour Ansible puisque c'est dans ce fichier de configuration (écrit en YAML toujours), que l'on va organiser et indiquer quelles actions nous souhaitons déclencher.
Les playbooks décrivent des « tâches » à exécuter sur des groupes de machines identifiés dans les inventaires, ils sont écrits à l'aide du format YAML.
La syntaxe Yaml
Yaml est un langage ou plutôt un format, qui permet de sérialiser des données afin qu'elles restent lisiblent pour nous. Les données sont organisées sous la forme de paire clé/valeur dans des listes ordonnées, il est de plus en plus utilisé notamment pour les fichiers de configuration.
Les playbooks
Afin de rentrer dans le vif du sujet nous allons écrire un playbook relativement simple utilisant un module que nous avons vu précédemment, le module ping. Nous avons vu que les modules Ansible peuvent être utilisés en ligne de commande pour exécuter une tâche ponctuelle mais rappelons que le but d'Ansible est en premier lieu, d'automatiser les choses et donc de les rendre réutilisables !
Structure générale d'un playbook
Créons un nouveau fichier que nous appellerons example.yml dans notre répertoire de travail (pour rappel de mon côté workspace/ansible) contenant:
---
- hosts: webservers
tasks:
- name: Check if host is alive # Description of the task
ansible.builtin.ping: ~La structure YAML permet une compréhension relativement aisée du contenu, on identifiera ainsi:
- Une clé principale appelée
hostspermettant de définir les « hôtes », les machines concernées par les tâches qui vont suivre (identifiées par leur groupe d'appartenance); - Une clé
taskspermettant de définir les différentes « tâches » ou actions que nous souhaitons déclencher sur nos machines.
Un bloc ainsi défini est appelé un « play ».
---
Vous l'aurez noté, les playbooks que nous rédigeons commencent tous avec trois tirets ---, ceux-ci marquent en effet en syntaxe Yaml, le début du document, ils sont donc indispensables à l'interprétation du fichier.
Ils permettent entre autres d'utiliser des directives en entêtes de fichier ou de disposer de plusieurs flux yaml dans un même fichier (le début de chaque flux étant indiqué par ces trois tirets).
Rappelez-vous nous pouvons traduire les instructions suivantes sous forme de tableaux:
array (
'hosts' => 'webservers',
'tasks' =>
array (
0 =>
array (
'name' => 'Check if host is alive',
'ansible.builtin.ping' => NULL,
),
),
)On constate encore plus aisément sous cette forme que la clé tasks permet de définir un nombre indéfini de « tâches » à exécuter, celles-ci ayant toujours au moins pour structure:
- Un nom (clé
name); - L'appel à un module ansible (ici nous faisons appel au module
pingutilisé précédemment) chaque module acceptant ou non des paramètres.
Les modules Ansible
Un module pour Ansible est un composant logiciel qui encapsule une tâche spécifique. Pour résumer, il s'agit d'un bloc de code qui est exécuté par Ansible pour accomplir une action donnée sur un système cible. On trouve notamment des modules capables de gérer des fichiers, d'exécuter des commandes ou encore de gérer des services. Ils peuvent être écrits dans divers langages de programmation, mais la plupart sont écrits en Python. Ansible vient avec une large gamme de modules intégrés pour gérer différents aspects des systèmes, des applications et des infrastructures.
La commande ansible-playbook
Nous avons déjà vu les commandes ansible et ansible-inventory au tour de ansible-playbook
En exécutant cette commande ansible-playbook example.yml -i inventories vous devriez obtenir la sortie suivante ou équivalente (si tout se passe bien).
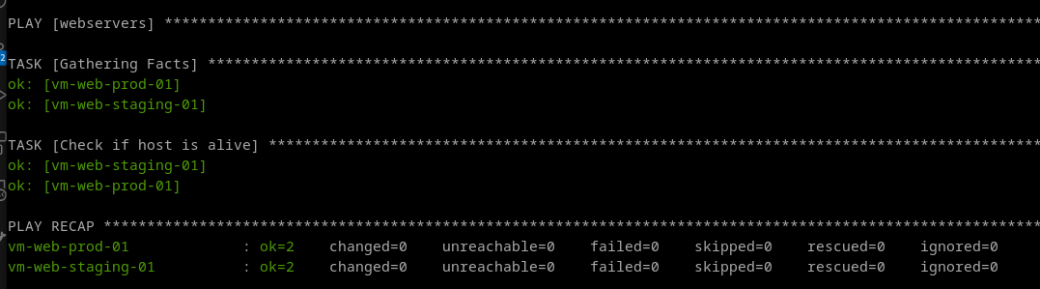
Nous venons donc de faire appel au module ping mais à l'intérieur d'un playbook. Ce que nous avons en retour et une sortie type d'Ansible sur laquelle on peut remarquer quelques informations toujours intéressantes (tout en bas) avec notamment:
ok: Le nombre de tâches (tasks) qui se sont correctement exécutées;changed: Le nombre de changements opérés sur nos machines cibles;unreachable: Le nombre de machines injoignables (par soucis de réseau par exemple);failed: Le nombre de tâches en erreur;skipped: Le nombre de tâches qui ont été ignorées (par exemple si une tâches ne remplie pas certaines conditions prédéfinies).
Les notions de « play » et de « tasks »
Il est bon de noté également qu'un playbook peut contenir plusieurs « plays » nous pouvons donc avoir des tâches attribuées à différents groupes cible comme ceci:
---
- hosts: webservers
tasks:
- name: Check if host is alive # Description of the task
ansible.builtin.ping:
- hosts: dbservers
tasks:
- name: Get stats of a file
ansible.builtin.stat:
path: /etc/hosts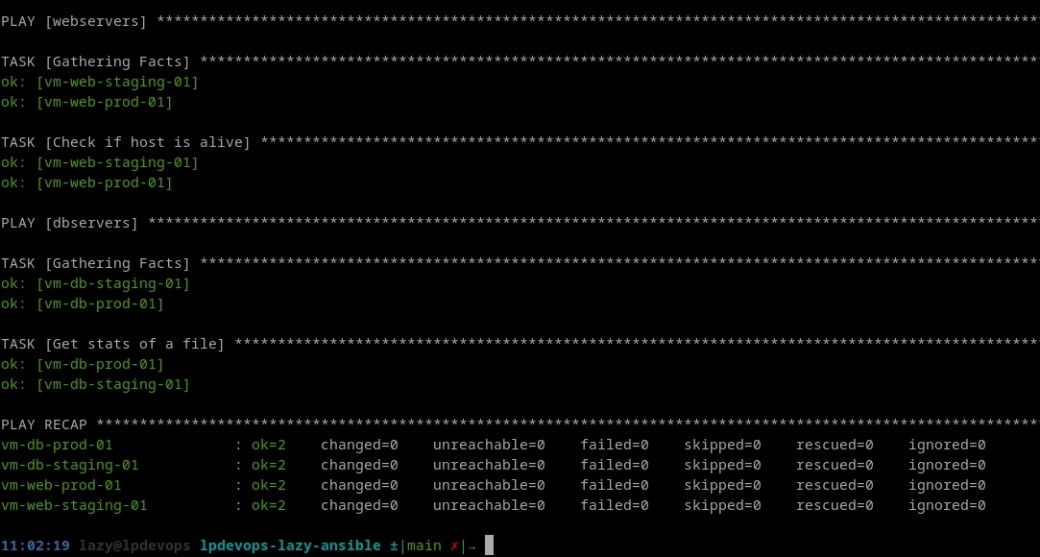
Nous avons dans ce cas de figure deux groupes chacun concerné par une « tâche »:
- Le groupe
webservers(contenant donc 2 machines) sur lequel nous exécutons le module ping; - Le groupe
dbservers(contenant également 2 machines) sur lequel nous exécutons le modulestat.
Le module stat
Le module stat permet d'exécuter la commande système stat sur un fichier du serveur cible. Il prends différents paramètres que l'on peut retrouver sur la documentation officielle dont le paramètre path qui lui est obligatoire.
Rappelez-vous également qu'un « play » peut exécuter plusieurs tâches les unes à la suite des autres, exemple:
---
- hosts: webservers
tasks:
- name: Check if host is alive # Description of the task
ansible.builtin.ping:
- name: Execute a simple command
ansible.builtin.shell: echo "Ansible was here !" > ansible.txt
- hosts: dbservers
tasks:
- name: Get stats of a file
ansible.builtin.stat:
path: /etc/hostsVous devriez, en jouant votre playbook (ansible-playbook example.yml -i inventories) obtenir une sortie équivalente à:
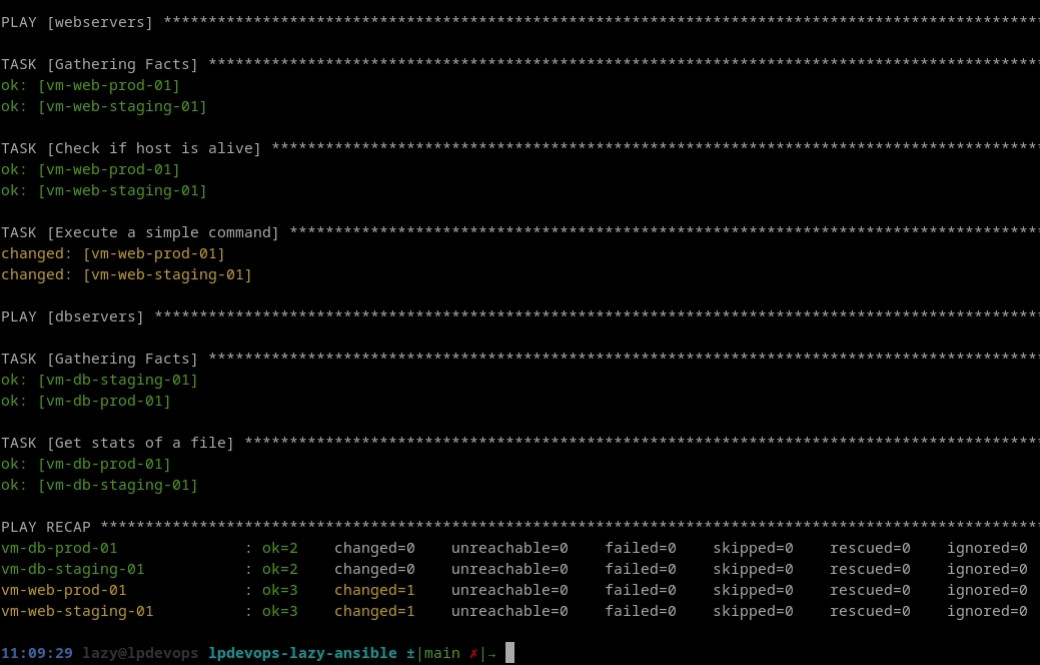
À la différence de nos premières tâches, l'utilisation du module shell a entrainé une modification de l'état des deux serveurs membres du groupe webservers qu'Ansible nous confirme à l'aide de son retour changed.
Visualiser les machines ciblées
Lorsque l'on dispose de playbook assez longs, il peut-être intéressant de vérifier la liste des hôtes concernés, c'est faisable à l'aide de la commande ansible-playbook example.yml -i inventories --list-host.

Il est également possible de lister les tâches avec l'option --list-tasks et bien évidemment de combiner ces deux options ansible-playbook example.yml -i inventories --list-tasks --list-hosts.
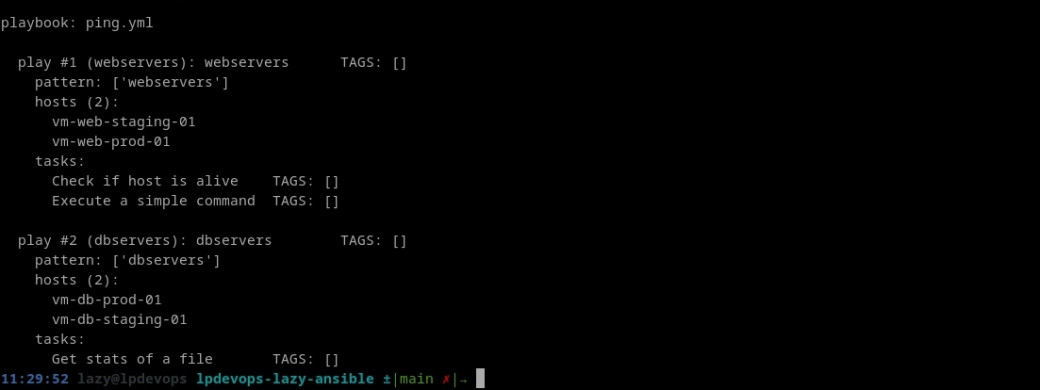
Vous aurez également remarqué la présence d'une information [TAGS] très utile dont nous parlerons par la suite ;)
Les tâches
Nous avons vu les principes fondamentaux du fonctionnement des « tasks » avec Ansible, mais celles-ci peuvent être plus complexes que celles que nous avons pu voir jusqu'à présent. Afin de s'en rendre compte nous allons déployer un serveur web Nginx sur nos instances web.
Nous allons ajouter une tâche dédiée dans un nouveau playbook que nous appelerons webservers.yml et qui contiendra les instructions suivantes:
---
- hosts: webservers
tasks:
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
update_cache: yes
state: presentEn l'exécutant (ansible-playbook webservers.yml -i inventories) vous devriez obtenir la sortie ci-dessous, Ansible nous indiquant qu'il a effectué une modification sur nos machines distantes:
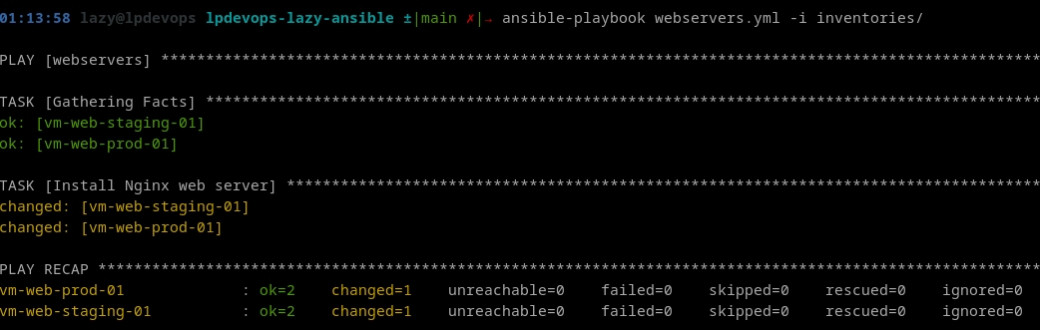
On notera l'utilisation du module apt (attention, utilisable bien évidemment uniquement avec les distributions basées sur Debian) accompagné de plusieurs paramètres;
name: le nom du paquet à installerupdate_cache: Indique qu'il faut effectuer une mise à jour de l'index des paquets avant l'installation.state: « L'état » dans lequel nous souhaitons avoir le paquet installé (present, absent, latest...)
Vous devriez également pouvoir interroger votre serveur web en utilisant l'IP de votre machine http://XXX.XXX.XXX.XXX.
L'escalade de privilèges
Avec cette tâche d'installation nous touchons une autre problématique qui est celle de la gestion des droits et notamment la modification de manière globale de l'état d'un système, ce qui relève normalement de la compétence du compte root, super administrateur des systèmes à base UNIX.
Si nous n'avons pas rencontré de problème jusqu'à présent c'est parce que nous utilisons un lazy Ansible pré-configuré avec certaines directives dans le fichier de configuration d'Ansible dont nous reparlerons un peu plus tard.
Il est toutefois possible le cas échéant, d'indiquer au niveau d'une tâche que celle-ci réclame des droits d'administrateur et qu'il faut déclencher une escalade de privilèges. Cela se fait en utilisant des clés réservées comme ci-dessous (en reprenant la tâche d'installation Nginx):
---
- hosts: webservers
remote_user: debian
tasks:
- name: Ensure Nginx service is started
service:
name: nginx
state: started
become: yes
become_user: root # This is the default value, so it's not mandatory hereOn remarquera les clés:
remote_user: Précisant l'utilisateur avec lequel se connecter à la machine;become: Indiquant s'il faut déclencher une escalade de privilèges;become_user: Indiquant le nom du compte utilisateur vers lequel faire l'escalade (Par défaut root).
Le mécanisme utilisé par Ansible pour faire son escalade est par défaut la commande sudo, il est possible de modifier ce comportement avec la clé become_method.
Organiser ses tâches
Nous avons vu que chaque « play » peut contenir plusieurs tâches, il faut savoir que celles-ci sont exécutées dans l'ordre dans lequel elles apparaissent et sur l'ensemble des machines qui correspondent à leur domaine d'application (un groupe ou une machine). Le but de chacune de ces tâches est d'exécuter un module (nous en avons déjà vu plusieurs, ping, stat, apt, shell), chaque module se devant d'être idempotent garantissant ainsi que peu importe le nombre de fois ou il sera exécuté il produira toujours le même résultat si ses paramètres d'entrée demeurent inchangés.
Il est important que chaque tâche dispose d'une clé name fournissant des instructions claires sur son rôle (pensez à la maintenance).
Ceci-dit il est bon de savoir que nos tâches peuvent être organisées de différentes manières et notamment en utilisant les différentes sections que l'on peut trouver dans un playbook:
pre_tasks: Contient les tâches à exécuter en premier;roles: Indiquant une liste de rôles à utiliser dans notre « play » (Nous verrons cette notion plus tard);post_tasks: Contenant les tâches à exécuter en dernier;handlers: Contenant des tâches déclenchées à la fin de chaque bloc ou section de tâches en fonction de certains évènements.
La section pre_tasks
Elle correspond à une exécution conditionnelle d'un bloc de code AVANT de lancer le « play », elle peut être chargée soit de vérifier des pré-requis soit de valider un état.
Souvenez-vous au moment d'installer notre paquet Nginx nous avions ajouté le paramètre update_cache afin de mettre à jour l'index des paquets. Mais nous avons une autre option qui se présente, plutôt que de faire figurer cette option sur chaque appel au module apt que nous aurons dans notre playbook, nous pouvons gérer la mise à jour de l'index des paquets avant de le jouer.
Modifions notre playbook webservers.yml de la façon suivante:
---
- hosts: webservers
pre_tasks:
- name: Updating APT cache index
ansible.builtin.apt:
update_cache: yes
tasks:
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
state: presentEt exécutons le, nous devrions obtenir la sortie suivante:
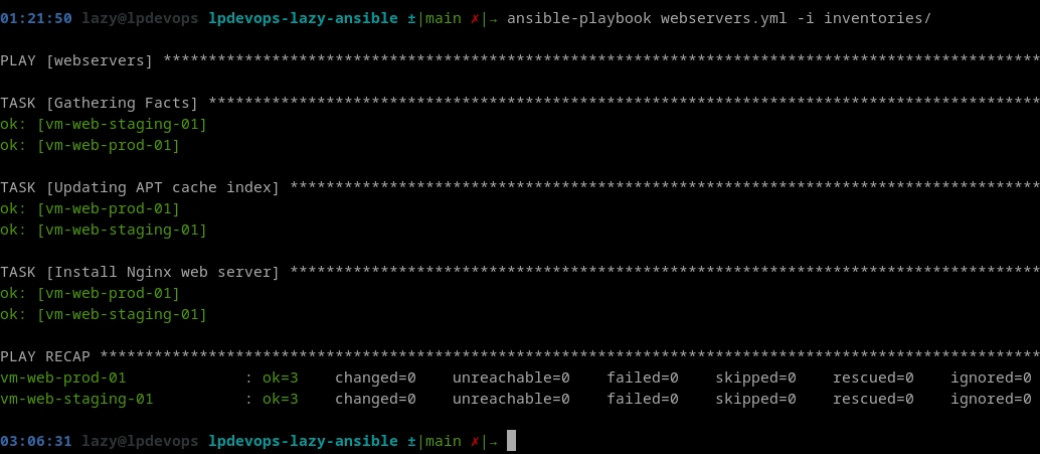
Où l'on constate qu'effectivement la première tâche exécutée est notre mise à jour d'index de paquets (nous parlerons plus en détails de la tâche « Gathering facts » lorsque nous aborderons les variables)
Nous ne détaillerons pas la section post_tasks puisqu'elle fonctionne exactement de la même manière, toutefois nous pouvons enrichir notre playbook avec de nouvelles instructions concernant nos instances de bases de données.
Pour cela nous avons plusieurs options:
- Soit tout concentrer dans notre playbook
webservers.yml, mais l'on pourra faire remarquer à raison, que le nom du fichier n'est plus en adéquation avec son contenu; - Soit créer un nouveau playbook dédié aux instances de bases de données
dbservers.yml.
Nous nous orienterons pour l'exemple, sur cette seconde option, nous créerons donc un fichier dbservers.yml à la racine de notre répertoire de travail dont le contenu ressemblera beaucoup à celui de webservers.yml.
- hosts: dbservers
pre_tasks:
- name: Updating APT cache index
ansible.builtin.apt:
update_cache: yes
tasks:
# MARIADB
- name: Install MariaDB server
ansible.builtin.apt:
name: mariadb-server
state: presentNotre nouveau playbook est bien evidemment « jouable » à l'aide de la commande ansible-playbook dbservers.yml -i inventories.
Les handlers
Bien, reprenons notre exemple d'installation d'Nginx, nous avons un paquet « tout neuf » auquel nous n'avons apporté aucune configuration pour l'instant. Imaginons à présent que nous souhaitions ajouter un fichier de configuration spécifique pour notre serveur web, pour notre exemple nous mettrons en place un fichier qui nous renvoie simplement un « état » de notre serveur Nginx.
En premier lieu nous allons créer un nouveau répertoire appelé files à la racine de notre espace de travail lui même contenant un répertoire nginx (histoire d'organiser un minimum les choses) dans lequel nous ajouterons le fichier status.conf contenant:
server {
listen *:8080;
root /usr/share/nginx/html;
access_log off;
location / {
return 404;
}
location = /nginx/status {
stub_status on;
}
}Modifions à présent notre fichier webservers.yml de la façon suivante:
---
- hosts: webservers
pre_tasks:
- name: Updating APT cache index
ansible.builtin.apt:
update_cache: yes
tasks:
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
state: present
- name: Nginx status configuration file
ansible.builtin.copy:
src: nginx/status.conf
dest: /etc/nginx/conf.d/status.confSi tout s'est déroulé correctement vous devriez avoir un fichier status.conf nouvellement créé par Ansible sur vos machines cibles dans le répertoire /etc/nginx/conf.d/.
Pour terminer nous pouvons vérifier que notre configuration fonctionne bien en interrogeant l'adresse: http://XXX.XXX.XXX.XXX:8080/nginx/status... ou pas !
Le module copy
Le module copy permet de gérer les fichiers de nos machines cibles à savoir leur création, leur suppression mais également leur type (n'oubliez pas, sur des systèmes UNIX tout est fichier !). Il permet notamment de transférer des fichiers de configuration vers des machines. Par défaut à son utilisation Ansible recherche le fichier passé en paramètre dans le répertoire files de l'espace de travail.
En l'état actuel vous devriez avoir pour toute réponse une page blanche, en effet bien que notre fichier de configuration ait été déposé sur le serveur, Nginx ne le prend pas encore en compte car le service n'a pas été redémarré. C'est là qu'entre en jeu les handlers !
Les handlers sont des tâches un peu particulières qui ne se déclenchent que lorsqu'elles sont notifiées. Complétons notre playbook de manière à obtenir la configuration suivante:
---
- hosts: webservers
pre_tasks:
- name: Updating APT cache index
ansible.builtin.apt:
update_cache: yes
tasks:
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
state: present
- name: Nginx status configuration file
ansible.builtin.copy:
src: nginx/status.conf
dest: /etc/nginx/conf.d/status.conf
notify:
- restart_nginx
handlers:
- name: restart_nginx
ansible.builtin.service:
name: nginx
state: restartedEn rejouant notre playbook ansible-playbook webservers.yml -i inventories nous constons que cela n'a rien changé ! Effectivement, comme dit précédemment un handler réagit à un évènement, dans notre cas à la modification du fichier status.conf. Comme nous ne l'avons pas modifié le handler n'a pas été notifié.
En introduisant une modification dans notre fichier (par exemple en modifiant la directive access_log pour la passer à off) nous devrions enfin pouvoir accéder à notre page de statut à l'adresse: http://XXX.XXX.XXX.XXX:8080/nginx/status.
Vous devriez également pouvoir constater l'exécution du handler sur la sortie Ansible:
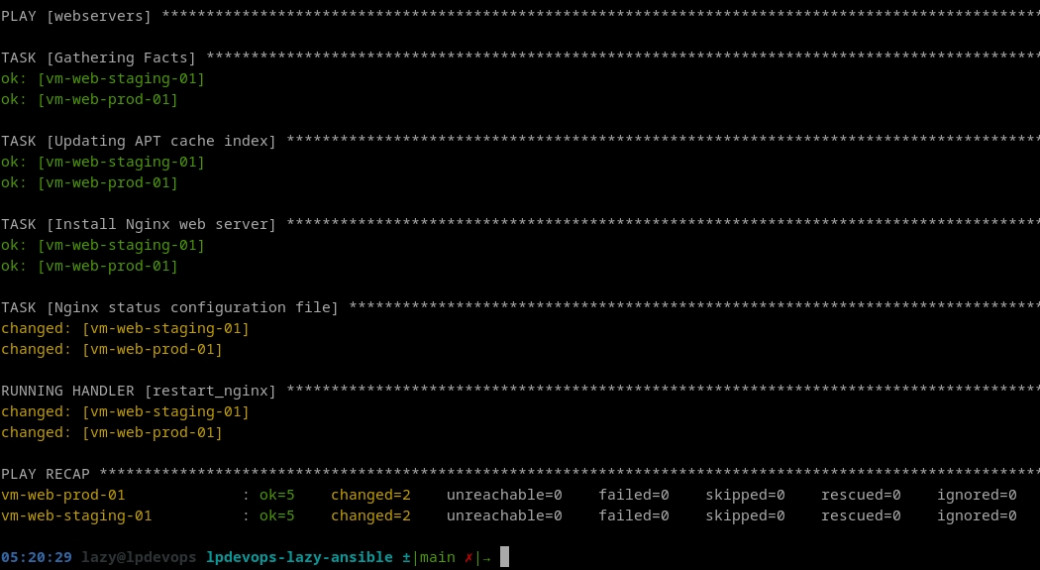
La directive « Notify »
Les actions de type notify sont déclenchées à la fin de chaque bloc de tâches d'un « play » donné, elles ne le sont bien évidemment qu'une seule fois même si elles sont appelée plusieurs fois.
Il est également possible d'ajouter à un handler une clé listen comme ci-dessous, celle-ci indiquant au handler « d'écouter » un thème spécifique permettant de regrouper plusieurs « handlers ».
handlers:
- name: restart_nginx
ansible.builtin.service:
name: nginx
state: restarted
listen: restart_http_stack
- name: restart haproxy
ansible.builtin.service:
name: haproxy
state: restarted
listen: restart_http_stackLes instructions import... et include...
Vous l'aurez compris, si l'on conserve l'ensemble de nos instructions dans un seul playbook celui-ci peut rapidemnent devenir volumineux et difficile à maintenir. Pour autant séparer nos instructions dans des playbooks dédiés conduit invariablement à dupliquer certains blocs d'instructions ce qui n'est pas non plus l'idéal, fort heureusement il est possible de résoudre ces problématiques de manière élégante en utilisant différentes instructions préfixées import_ et include_.
Avant de réorganiser nos travaux il est important de bien comprendre la différence entre les deux:
- Les instructions de type
import_*sont « pré-traitées » au moment où les playbooks sont parcourus et donc avant leur exécution; - Les instructions de type
include_*sont traitées au moment où elles sont rencontrées durant l'exécution.
Réorganisons à présent nos playbooks en tenant compte de cette nouvelle information:
- L'instruction de mise à jour de notre index APT dans notre
pre_taskspeut-être considérée comme une tâche commune à l'ensemble des machines; - Il est intéressant de pouvoir « jouer » de manière indépendante les deux playbooks
webservers.ymletdbservers.ymlmais il peut aussi être « sympa » de pouvoir les appeler de manière groupée; - Les handlers pourront être potentiellement notifiés de manière transverse par de futures tâches de configuration.
Nous déplacerons donc nos tâches « communes » dans un playbook dédié common.yml qui contiendra donc:
- name: Updating APT cache index
ansible.builtin.apt:
update_cache: yesNous supprimerons bien évidemment des playbooks webservers.yml et dbservers.yml les instructions correspondantes.
Nos handlers eux, finiront dans un nouveau playbook handlers.yml comme ci-dessous:
- name: restart_nginx
ansible.builtin.service:
name: nginx
state: restarted
- name: restart_mariadb
ansible.builtin.service:
name: mariadb
state: restartedQuant à nos deux playbooks principaux nous les modifierons légèrement en y ajoutant:
- l'inclusion des pre_tasks (
common.yml); - l'inclusion des handlers (
handlers.yml); - un playbook « global » afin de les déclencher.
Respectivement:
---
- hosts: webservers
pre_tasks:
- ansible.builtin.import_tasks: common.yml
tasks:
# NGINX
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
state: present
- name: Nginx status configuration file
ansible.builtin.copy:
src: nginx/status.conf
dest: /etc/nginx/conf.d/status.conf
notify:
- restart_nginx
handlers:
- ansible.builtin.include_tasks: handlers.yml---
- hosts: dbservers
pre_tasks:
- ansible.builtin.import_tasks: common.yml
tasks:
# NGINX
- name: Install MariaDB server
ansible.builtin.apt:
name: mariadb-server
state: present
handlers:
- ansible.builtin.include_tasks: handlers.ymlNous créerons enfin pour terminer un dernier playbook main.yml contenant:
- ansible.builtin.import_playbook: webservers.yml
- ansible.builtin.import_playbook: dbservers.ymlNous pouvons à présent jouer l'ensemble avec la commande: ansible-playbook main.yml -i inventories !
Tout semble fonctionner ! Mais est-ce vraiment le cas ?
Modifiez à nouveau le fichier de configuration status.conf destiné à Nginx et relancer le provisionning.
Vous devriez vous retrouver avec l'erreur ERROR! The requested handler 'restart_nginx' was not found in either the main handlers list nor in the listening handlers list !
En effet nous avons utilisé une directive de type include pour inclure notre fichier de handlers, or nous avons vu que ces instructions ne sont pas « pré-traitées ». Ansible lorsqu'il parcours notre playbook rencontre donc l'instruction:
notify:
- restart_nginxAVANT que notre fichier handlers.yml et donc qu'Ansible ait connaissance de l'existance de ce handler !
Pour corriger ce comportement il faudra donc dans notre cas utiliser la directive:
handlers:
- ansible.builtin.inport_tasks: handlers.ymlTaguer ses tâches
Nous venons de voir la possibilité de « diviser pour réorganiser » nos tâches, mais il existe également la possibilité de « taguer » nos tâches de manière à les déclencher de manière ciblée, ouvrant également la possibilité de les exécuter de façons transverses si celles-ci appartiennent à plusieurs playbooks différents.
Nous verrons qu'ils sont très utiles voir indispensables dès lorsque nous aurons abordé la notion de roles.
Reprenons notre exemple précédent où nous disposons de deux playbooks principaux distincts webservers.yml et dbservers.yml nous les modifierons de façon à « taguer » nos différentes tâches comme ci-après:
Webservers:
...
tasks:
# NGINX
- name: Install Nginx web server
ansible.builtin.apt:
name: nginx
state: present
tags:
- nginx
- installation
- name: Nginx status configuration file
ansible.builtin.copy:
src: nginx/status.conf
dest: /etc/nginx/conf.d/status.conf
notify:
- restart_nginx
tags:
- nginx
- configuration
...Dbservers:
...
tasks:
# NGINX
- name: Install MariaDB server
ansible.builtin.apt:
name: mariadb-server
state: present
tags:
- db
...Utilisation
Maintenant que nos tags sont définis nous sommes en capacité de les exploiter en ajoutant l'option --tags à notre exécution ce qui nous donnera par exemple:
ansible-playbook main.yml -i inventories --tags "nginx,db".
Il est également possible d'ignorer certains tags avec l'option --skip-tags:
ansible-playbook main.yml -i inventories --skip-tags db.
Les tags never and always
Ansible dans son fonctionnement, prévoit des tags réservés:
always, permet de systématiquement jouer une tâche sauf lorsqu'elle est explicitement exclue à l'aide de l'option--skip-tags;neverà l'inverse, permettra de ne jamais jouer les tâches concernées à moins de le spécifier explicitement à l'aide le l'option--tags.
La tâche « Gathering facts »
La tâche « Gathering fact » porte le tag « always » par défaut qui lui permet d'être jouée systématiquement, il est donc possible d'ignorer cette tâche via les options vues ci-dessus. Toutefois son absence peut entrainer un mauvais fonctionnement (voir une erreur) des différentes tâches devant être exécutées à sa suite.
Point de progression
Nous savons à présent gérer:
- L'installation d'un environnement Ansible;
- Utiliser l'inventaire;
- Créer des playbooks.
Nous pouvons toutefois encore apporter un peu de dynamisme à ces premières notions par l'introduction de variables dont nous parlerons dans la suite.
Aller plus loin avec les sources
- https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_intro.html
- https://docs.ansible.com/ansible/2.9/modules/list_of_all_modules.html
- https://yaml.org/spec/1.2.2/#912-document-markers
- https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_privilege_escalation.html
- https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_handlers.html#handlers
- https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_tags.html
Une typo ? Modifier cet article sur Github